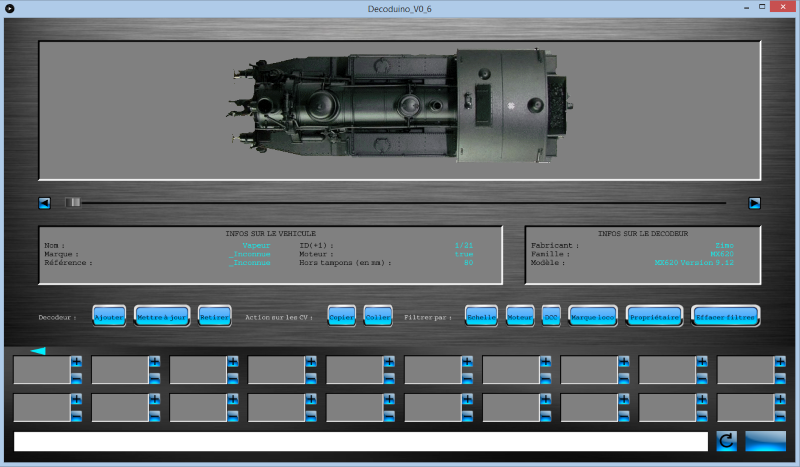
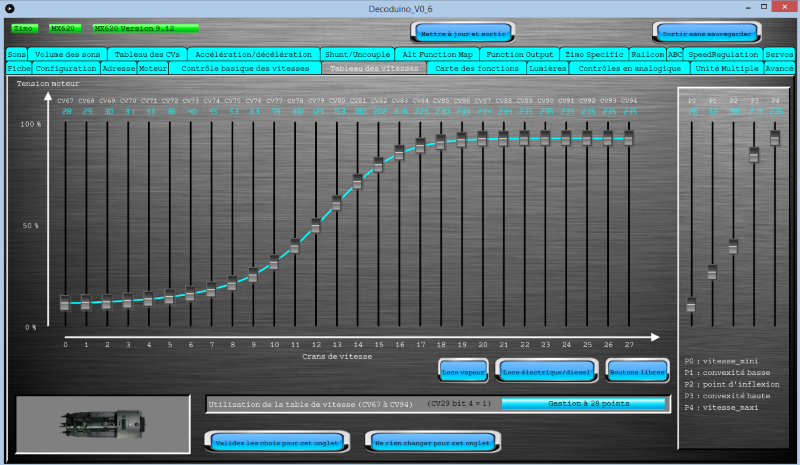
J'ai essayé de relever le défi que m'avait lancé msport le 03/06/20

Je vais maintenant décrire un "premier jet", assez costaud quand même, d'une version Processing de ressemblant à Decoder Pro's. Ne rêvez pas, toutefois, ce n'est pas fini.
Et même, j'aurais besoin de votre aide (un pb simple et un plus compliqué).
Mais on est sur un site communautaire, n'est-ce pas ?

La norme DCC :
Avant ça, j'ai commencé par la base : le DCC
Je ne vais pas ici faire un historique complet, mais noter quelques points :
Inventé au départ par Lenz, mais le fait que Märklin l'ait pris pour ses modèles Trix n'est pas étranger à son succès.
Puis la NMRA (National Model Railroad Association), l'organisme de normalisation américain, l'a pris sous son aile et c'est maintenant LA norme numérique mondiale.
La dernière version de cette norme date du … 20/12/2012.
Et, plutôt que d'explorer internet qui regorge de détails de-ci, de-là, malheureusement parfois contradictoires, je me suis attelé d'abord à une traduction la plus proche possible de LA norme, sans y ajouter des élucubrations diverses, des interprétations et des raccourcis saisissants…
Comme ça, on n'oublie rien.
On a, en tout, 1024 CV (Configuration Variables = variables de configuration) et j'ai gardé le terme CV, même en français, car c'est maintenant entré dans le langage courant (des modélistes).
Je pense que c'est du genre féminin (ce serait logique), mais on voit aussi le masculin.
Et, contrairement au mot "COVID", l'Académie ne donnera pas son avis. On peut dire les deux.
Rassurez-vous, sur ces 1024 CV, 650 CV (!) sont "pour une utilisation future" dans la norme.
Puis 163 CV sont réservés aux fabricants de décodeurs et, donc, pas dans la norme non plus.
Il ne reste "que" 211 CV (!) définis.

Vous verrez en PJ ma traduction.
Comme tous ces CV n'ont pas un intérêt immédiat, j'ai commencé par les plus utiles, quitte à enrichir au fur et à mesure des besoins. C'est un choix de départ.
Qui dit DCC dit aussi décodeurs et, donc, fabricants de décodeurs qui s'en sont donné à cœur joie pour remplir les 163 CV qui leurs sont alloués.
Dans Decodeur Pro's, on recense 60 fabricants et près de 1 000 décodeurs.
Et, pour chaque décodeur, la quasi totalité des spécificités sont prises en compte.
Franchement, chapeau !

Mon projet est beaucoup plus modeste

, surtout à ce stade.
Mais il contient les bases pour aller plus loin.
La gestion d'un parc de véhicules :
Une autre fonctionnalité de ce programme, c'est qu'on peut gérer un parc de véhicules.
J'ai bien dit "véhicules" et pas "locos" d'une part à cause du fait qu'un wagon/une voiture peut aussi avoir un décodeur (allumage, …) et qu'on peut utiliser ces véhicules dans des compositions de trains qui sera gérée.
Un autre défi, plus vieux, celui-là, c'est celui de CATPLUS, le 29/11/19 et la gestion du réseau de son ami Gérard et ses … 600 wagons (!). Autant dire un club !

J'ai démarré cet aspect, mais il me manque encore quelques jours pour le mener à bien.
Les bases de Decoduino :
Pour gérer tout ça, il faut des fichiers pour sauvegarder toutes ces infos.
La structure des répertoires est la suivante :
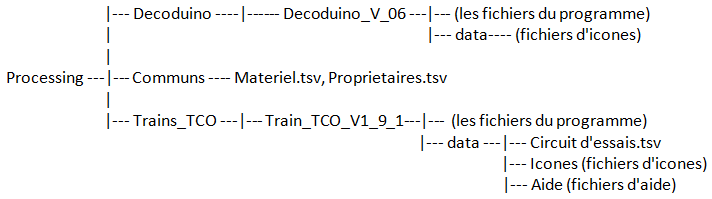
On a un répertoire Processing qui contient 3 sous-répertoires :
1°) Decoduino
C'est un répertoire générique qui contient toutes les versions des programmes Decoduino.
En ce moment, j'en suis à Decoduino_V_06.
Chaque version contient les fichiers Processing (en *.pde) et un répertoire data qui contient les fichiers d'icones
2°) Trains_TCO
C'est un répertoire générique qui contient toutes les versions des programmes Train_TCO
En ce moment, j'en suis à la version Train_TCO_V1_9_1
Chaque version contient les fichiers en Processing (en *.pde) et un répertoire data qui contient les plans de réseau (par exemple Circuit d'essai.tsv) et deux sous-répertoires contenant les fichiers d'icones et les fichiers d'aide.
3°) Communs
Ces deux programmes utilisent des fichiers communs qui sont :
-> Matériel.tsv (tous les véhicules et CV)
-> Propriétaires.tsv (les identifiants des propriétaires)
Évidemment, Train_TCO n'est absolument pas nécessaire au fonctionnement de Decoduino.
J'en parle ici juste pour montrer qu'il y a des fichiers communs aux deux programmes.
D'autre part, les fichiers communs ne changement pas si on change de version Decoduino (ou de version Trains_TCO)
Fichiers communs :
Processing utilise des fichiers en ".tsv" (Tabulation Separated Variables = variables séparées par des tabulations).
Et c'est le format natif des fichiers ".txt" (texte) dans Excel.
Pour LIRE un fichier ".tsv" dans Excel, il suffit de l'ouvrir ! Qui dit mieux ?
Pour ECRIRE, il faut ruser un peu.
1°) Depuis Excel, on sauve en ".txt" ("Texte (séparateur : tabulation) *.txt", pour être précis)
2°) On renomme le fichier en ".tsv".
Le premier fichier est le plus important : Materiel.tsv
Champs ("colonnes" dans Excel) :
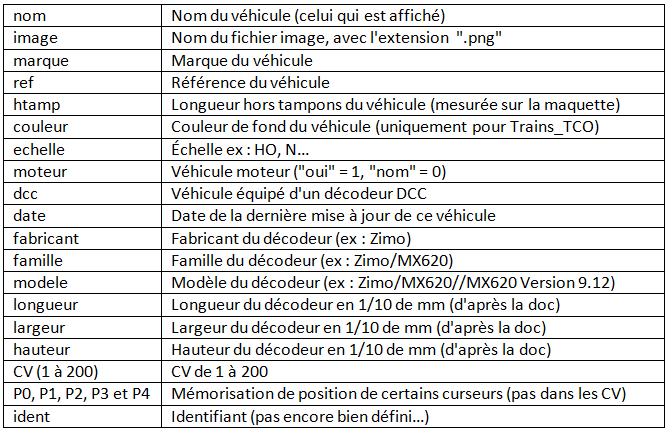
Les noms de champs ne doivent pas être modifiés, ni leur ordre. Ils n'ont pas d'accent.
Remarques :1°) Dans Processing, les fichiers ".tsv" ne contiennent des données de seulement deux types :
"String" ou "Int". Pas de booléens, ni de virgule flottante.
D'où le fait que "moteur" est en "0" ou "1", par exemple.
D'où le fait que les dimensions sont en 1/10 de mm
2°) J'impose l'extension ".png" car c'est la plus courante acceptant des fonds invisibles, ce qui est indispensable. Exit ".jpg" !
3°) Ne pas croire que la marque du véhicule est la même que le nom du fabricant du décodeur.
J'ai une loco Fleischmann qui a, d'origine, un décodeur Zimo.
4°) fabricant, famille, modele : je garde les appellations de Decoder Pro's.
Notez qu'il y a un seul "/" entre fabricant et famille et deux "/" entre famille et modele.
C'est indispensable.
5°) On peut se demander pourquoi on note les dimensions des décodeurs (surtout avec une telle précision) :
Parce que l'une des questions principales est d'identifier avec exactitude quel modèle de décodeur est dans ma loco. J'y reviendrai.
Dernière remarque, la plus importante :A tout moment, on doit avoir une bijection entre le contenu des CV du fichier Materiel.tsv et le contenu réel du décodeur.
C'est le principal intérêt de ce programme.Deuxième fichier : Propriétaires.tsv
Champs ("colonnes" dans Excel)

Les CV105 et CV106 sont réservés à l'usage de l'utilisateur
Dans un club, on peut très bien avoir 2 locos identiques qui peuvent avoir 2 propriétaires.
On mettra dans le CV105 les identifiants de chaque propriétaire.
Et comme un numéro, ça n'est pas très causant, il faut bien le nom en clair.
D'où ce fichier.
Je n'ai pas développé plus loin cette fonction pour l'instant. Mais ce serait assez facile.
Remarque :N'utiliser que le CV105 "limite" le club à 255 adhérents.
En utilisant les deux CV, on pourrait avoir 65 536 adhérents (!!)
Développement prévu pour ces fichiers :Actuellement, LE SEUL moyen d'ajouter un véhicule est de l'ajouter dans le fichier Materiel.tsv
De même pour supprimer un véhicule.
En fait, les 16 premières colonnes (tout sauf les CV et P0/P4) ne sont modifiables que directement via Materiel.tsv
C'est un peu gênant, mais je pense que développer le programme et ses fonctionnalités est plus urgent.
Le programme :
Puisque la gestion des répertoires est différente en Windows et Mac, elle n'est pas identique non plus dans Processing.
Ce qui fait que mon programme ne fonctionne pas avec Mac…
J'avais dit que j'avais besoin d'aide tout au début de ce post. C'est là que se situe le problème simple.
J'aurais donc besoin qu'un utilisateur Processing sur Mac me dise quoi faire.
Voilà le setup() :

Tout d'abord, on ouvre en size(1366, 768, P2D);
Cette taille permet l'affichage sur tous les ordinateurs.
La fonction
sketchPath("") permet de remonter jusqu'à la racine de l'arborescence.
Sur mon ordi Windows, le
println(Repertoire_Decoduino); donne :
R:\Documents publics\_Trains\Processing\Decoduino\Decoduino_V0_6\
Vous noterez qu'on est bien avec des "\", le cas normal dans Windows.
Puis je crée toutes les polices nécessaires.
Cela pourrait paraître superflu et on pourrait n'en créer qu'une seule et l'adapter à chaque fois qu'on s'en sert.
L'expérience montre que si on fait comme ça, les textes sont flous…
D'où cette façon de procéder.
Mais, en y regardant de plus près, ce sont les "/" qu'il faut utiliser pour descendre dans l'arborescence !
Puis je retire les 25 derniers caractères pour les remplacer par Communs\\ , oui, avec deux "\" !!
Là, ça ne sera pas pareil pour Mac.
Sur mon ordi Windows, le
println(Repertoire_Communs); donne :
R:\Documents publics\_Trains\Processing\Communs\
Plus loin, dans le programme, on va charger le fichier "Matériel.tsv"
La ligne correspondante est, dans Windows :
Materiel = loadTable(Repertoire_Communs+"Materiel/Materiel.tsv", "header, tsv");Je pense que c'est compatible Mac.
Et, quand on sauve :
saveTable(Materiel, Repertoire_Communs+"Materiel/Materiel.tsv");Là aussi, je pense que c'est compatible Mac.
J'arrête là pour aujourd'hui. Je continuerai quand le programme marchera dans les deux configurations Windows et Mac.
Et ça me laissera le temps de peaufiner.
Pour vous faire patienter, voici deux photos :